Finally done: rut and rsh flies better at self-learning
on Monday, January 22nd, 2024 1:36 | by Björn Brembs
At long last, I got all the flies together that we need for sufficient statistical power. As the preliminary data had indicated, WTB flies don’t learn with the short training, while rut and rsh flies do just fine.
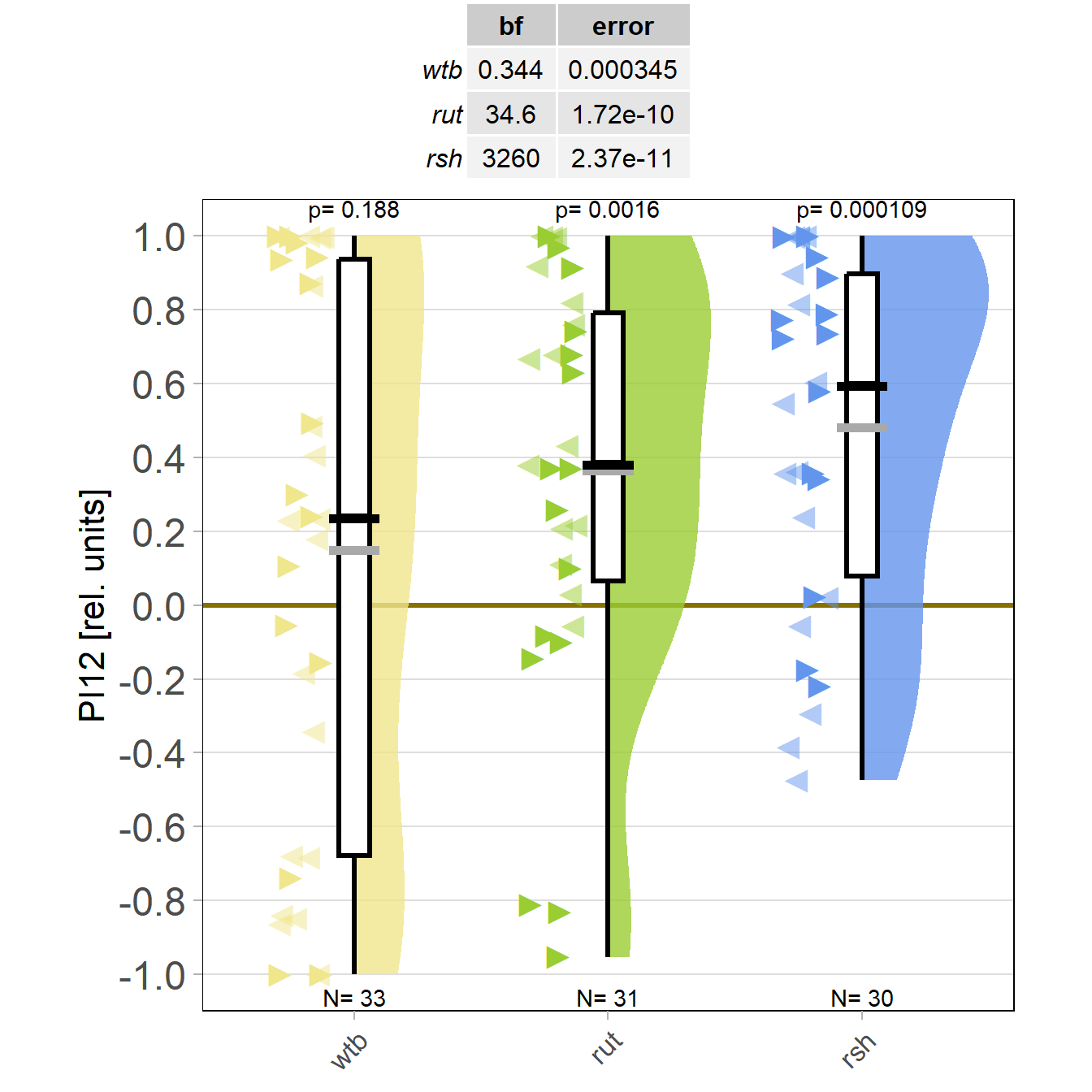
However, this may be due to genetic background effects, so we need to check the CRISPR mutants.

Category: Operant learning, operant self-learning, Radish | No Comments
Starting it back up
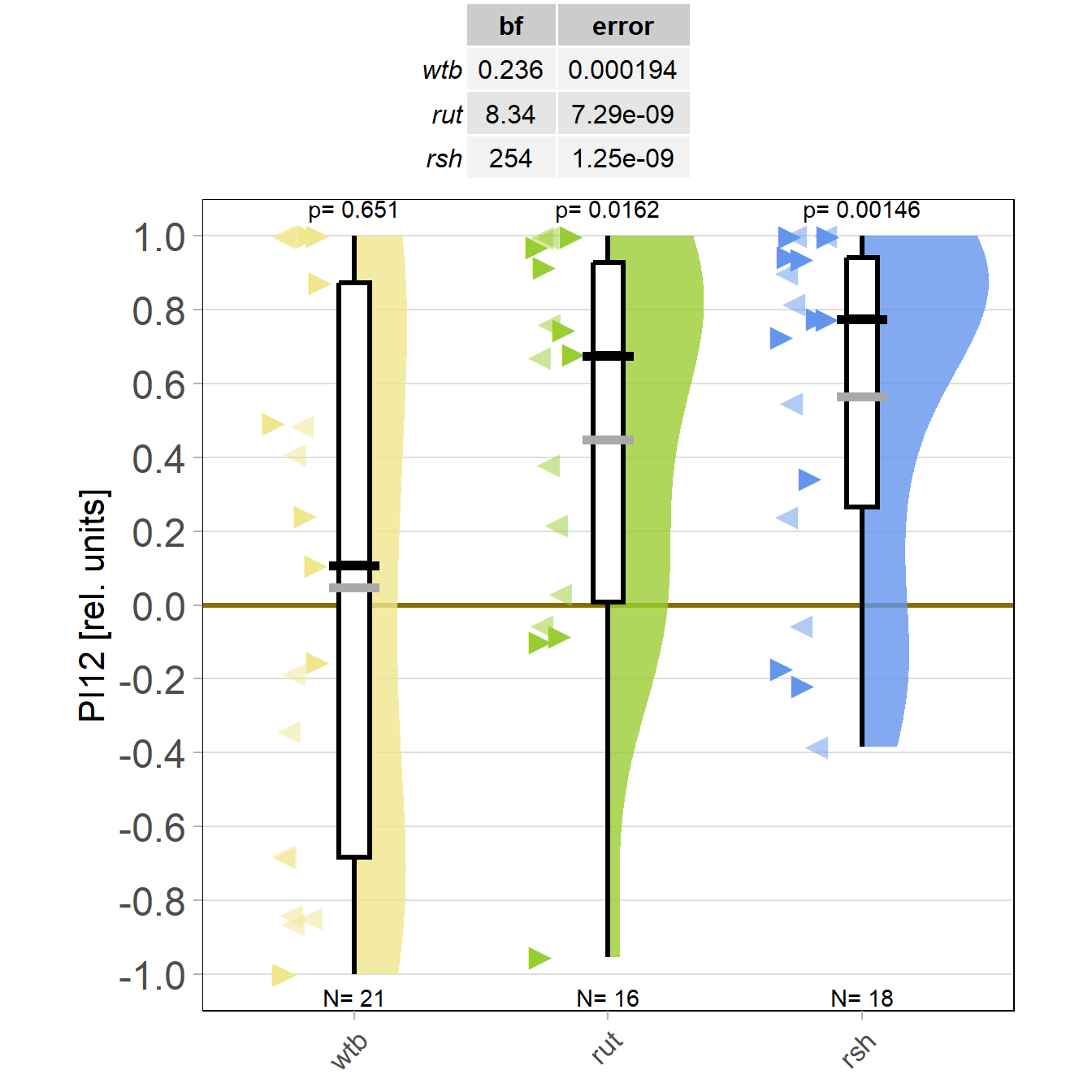
on Monday, December 11th, 2023 11:34 | by Björn Brembs
Last week, the torque mete ran for two days and I managed to record a few radish flies:
Category: Operant learning, operant self-learning | No Comments
Rover vs. Sitter self learning after 4 minutes training
on Monday, October 16th, 2023 10:39 | by Radostina Lyutova
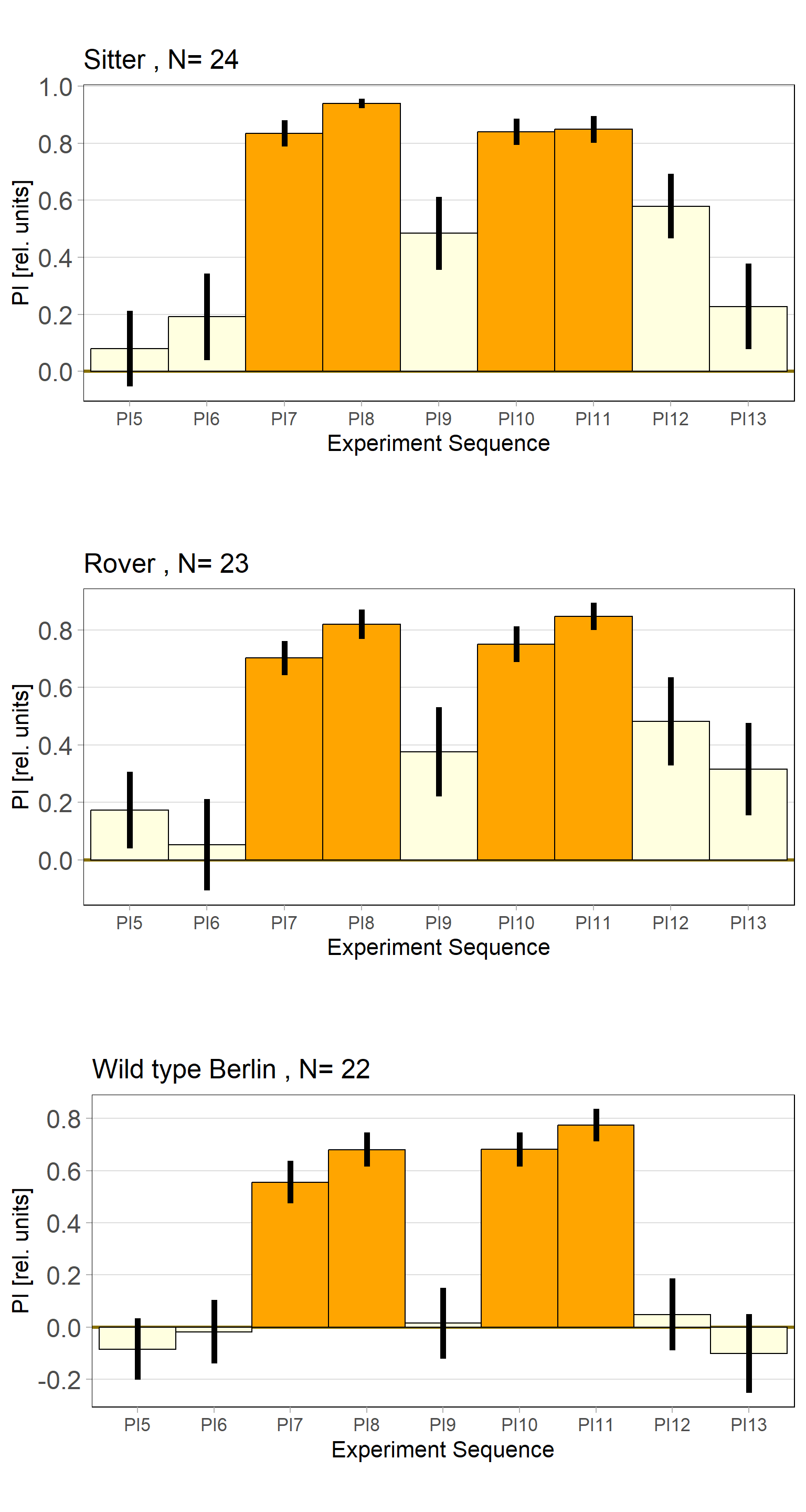

Category: flight, Habit formation, Memory, Operant learning, operant self-learning, Rover/Sitter | No Comments
Slowly collecting the mutants
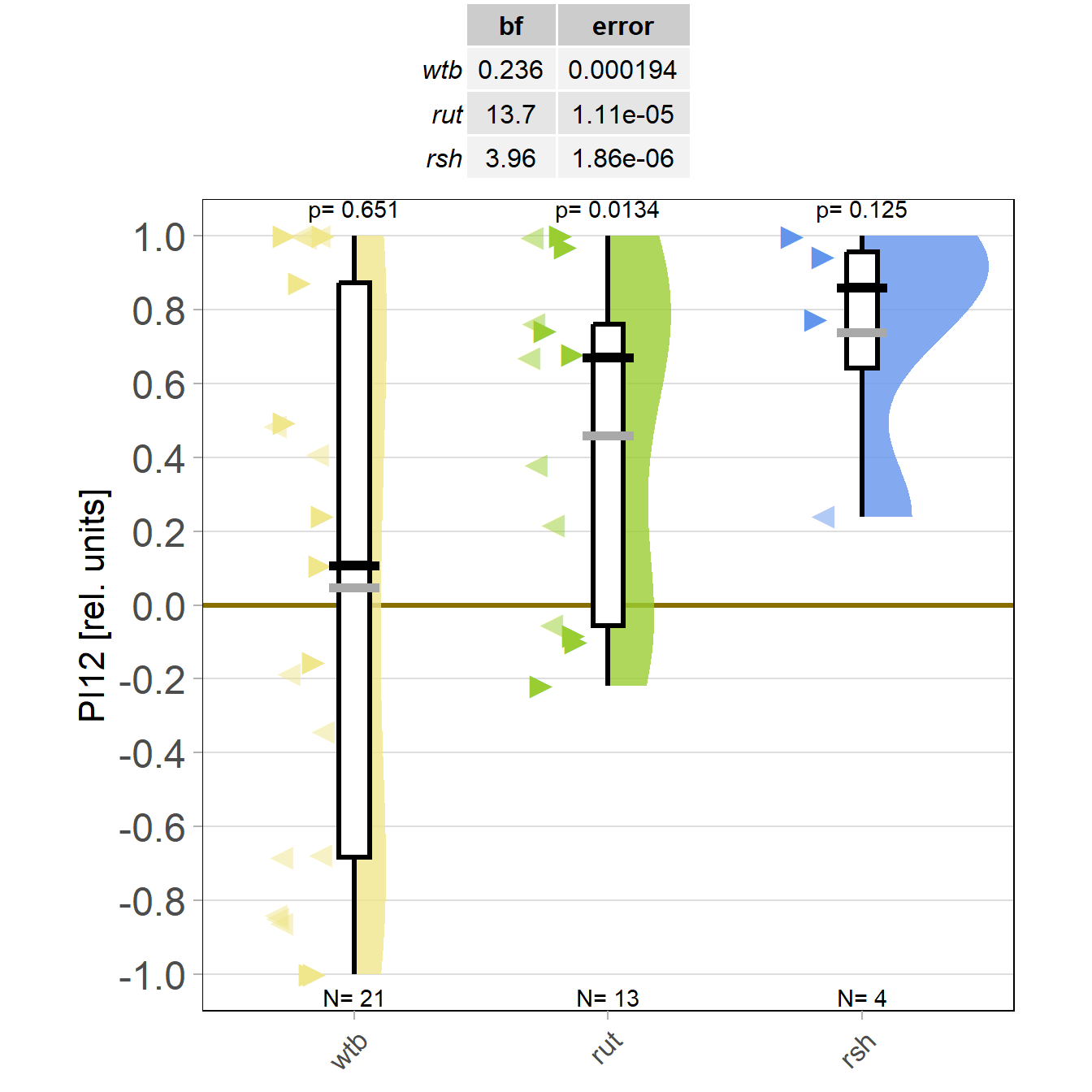
on Friday, October 13th, 2023 6:13 | by Björn Brembs
Finally, thanks to Marcella gluing to fly wheels instead of one, the mutant data are starting to roll in on the shortened self-learning experiment:
Category: Operant learning, operant self-learning | No Comments
First mutant data coming in
on Friday, October 6th, 2023 2:29 | by Björn Brembs
Short yaw torque learning, i.e., only one minute per period. Orange: training, yellow: test. WTB: wild type Berlin, rut: rutabaga learning mutants. With this short training of only 4 minutes, wild type flies show no torque preference in the after training, while at least the first few rutabaga flies show such a preference:
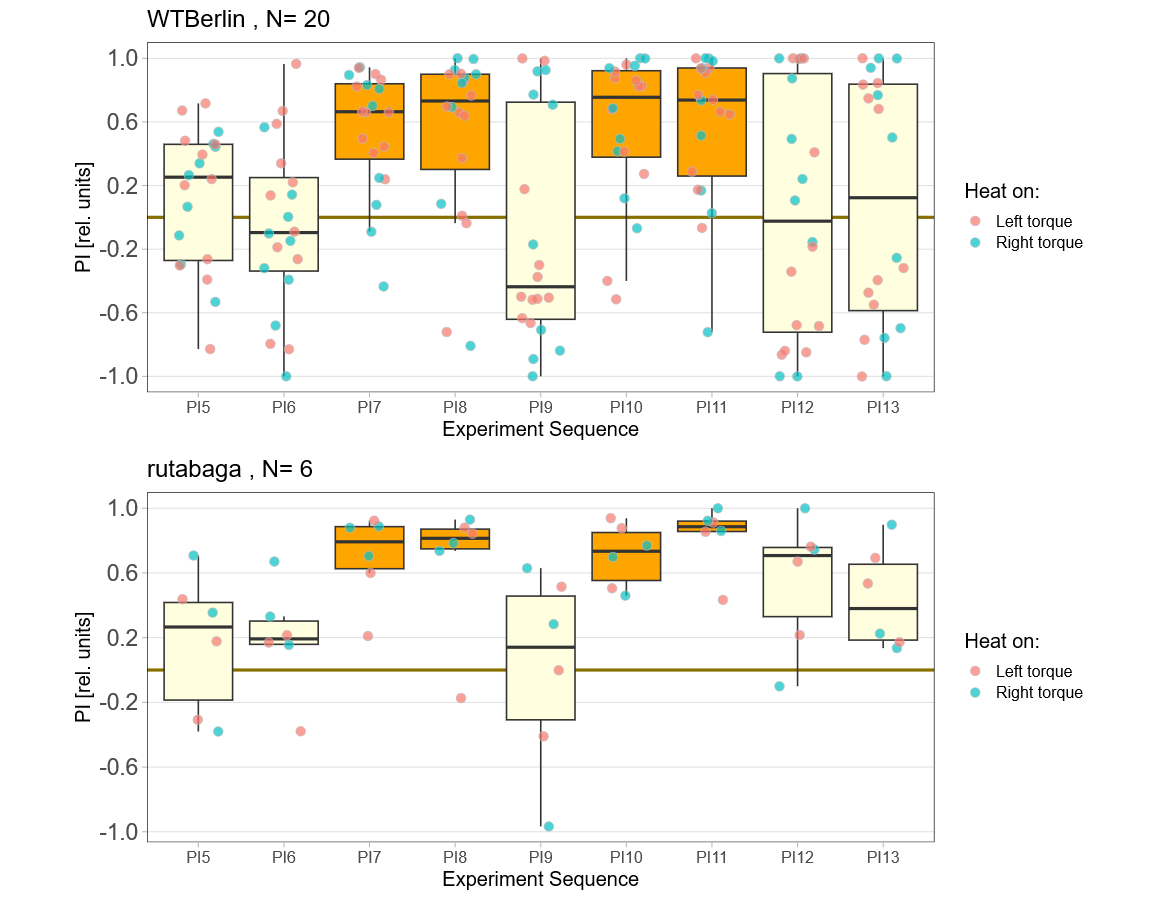
So far, I only could get one radish fly to make it through the experiment, so I cannot display it here.
Category: Operant learning, operant self-learning | No Comments
Bachelor Blog / #7 offspring
on Monday, October 2nd, 2023 10:51 | by Ellie
Below you can find the data I collected from the offspring flies:
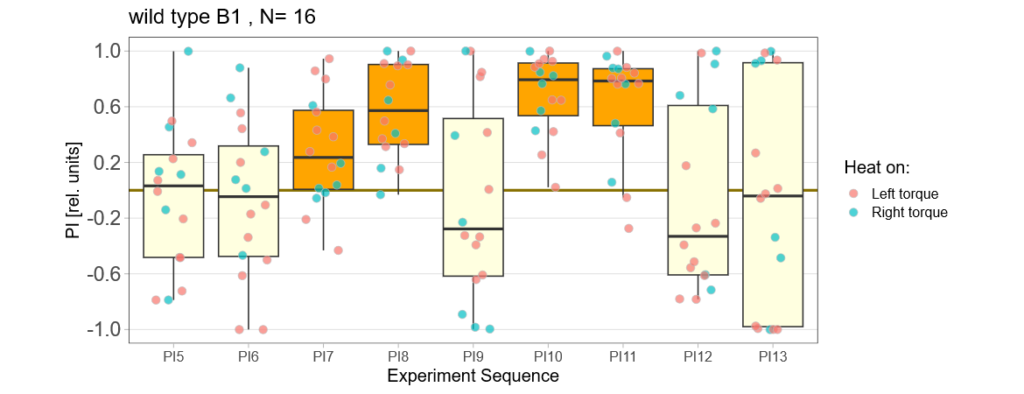
-> offspring from trained parents
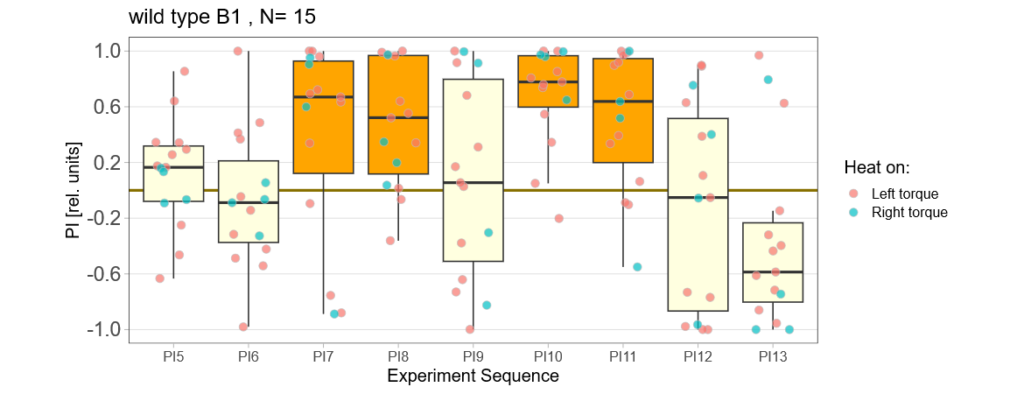
-> offspring from untrained parents
(I left out data from flies that showed negative preference during two training periods in a row)
Four minutes not enough
on Friday, September 29th, 2023 4:20 | by Björn Brembs
Eight minutes of yaw torque training work just fine for both wild type and mutant flies:
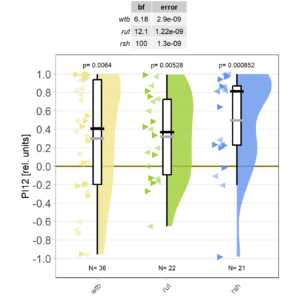
Reducing the training to four minutes is not enough for wild type flies:
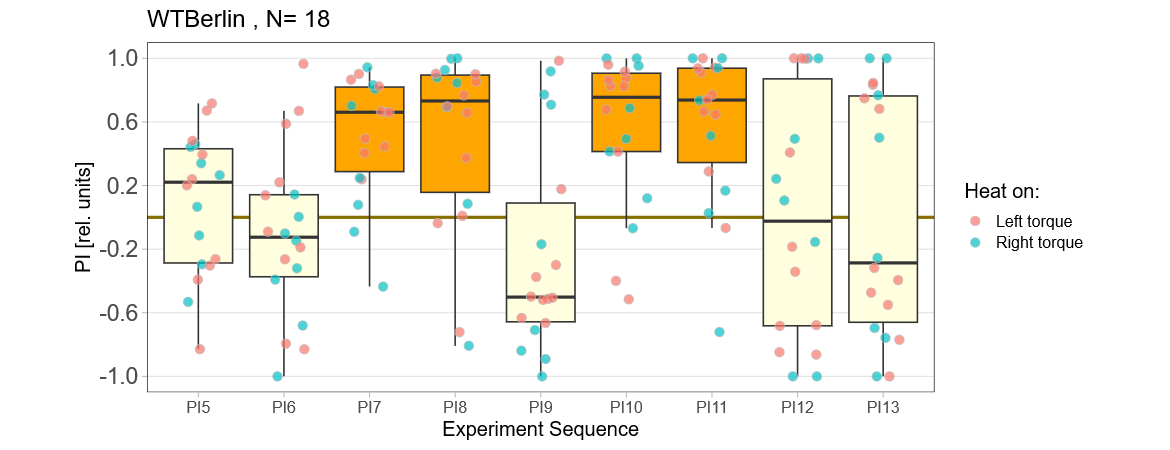
Now it will be exciting to see if the mutants still do what they did many years ago: learn better than wild type.
Category: Operant learning, operant self-learning | No Comments
Bachelor Blog / #6 playing around
on Monday, September 18th, 2023 12:51 | by Ellie
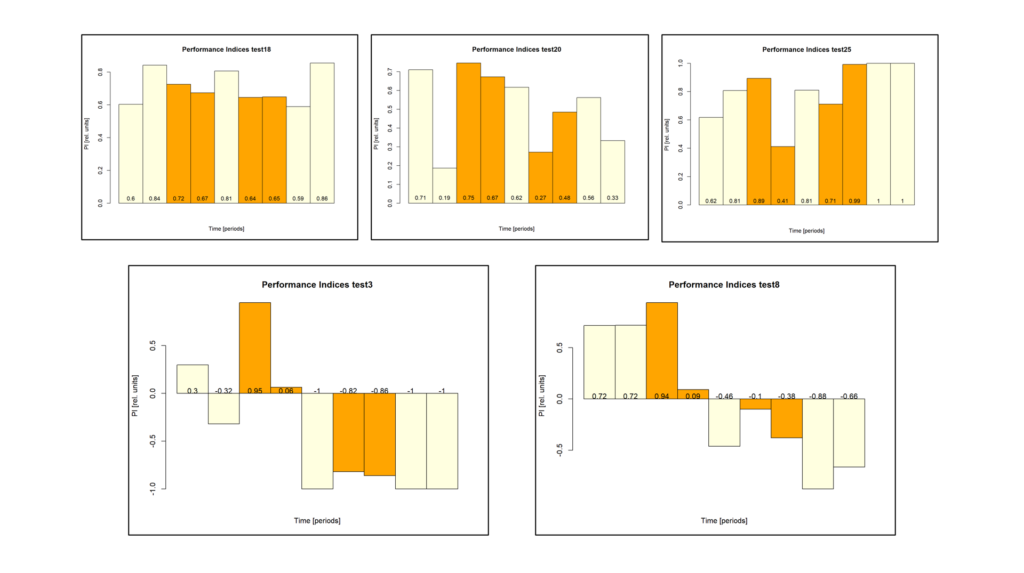
Since the results I got after training the parental flies looked a bit odd on first sight I decided to take a closer view…
First I excluded some weird animals that either showed a larger preference for one side than avoidance or showed no avoidance two training periods in a row:
Next I compared the behavior of flies that showed avoidance but no learning with the behavior of the remaining flies:
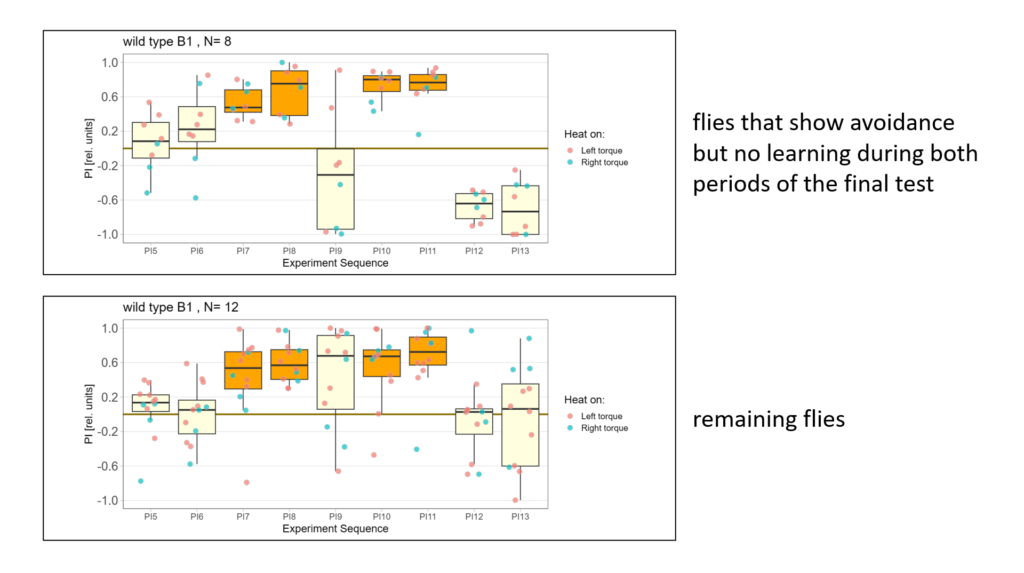
-> Avoidance is almost the same but note the first test period!
Lastly I split the data according to male and female flies. Here is what I got:
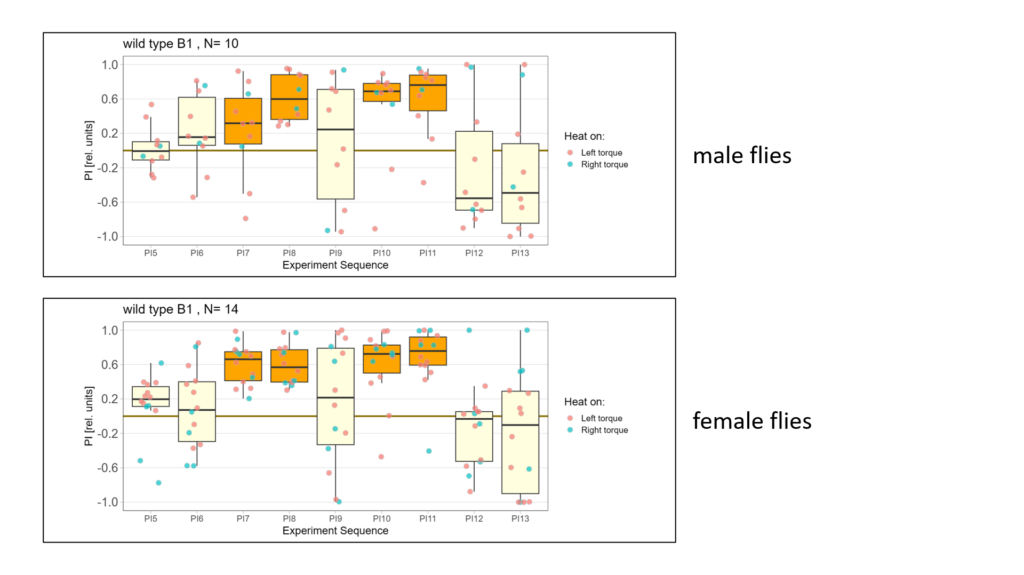
-> Looks a bit like there is negative learning in the male flies however I don´t have enough data to be sure…
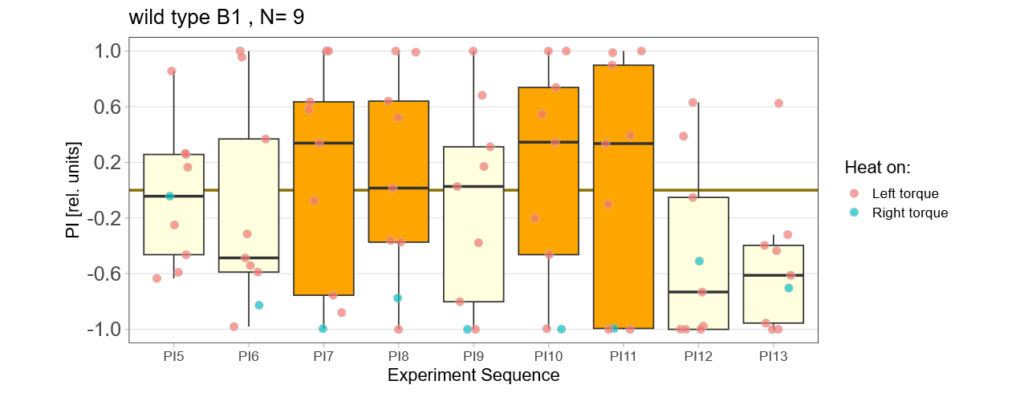
As an overview here are all the flies (except for the excluded ones) together again:
Bachelor Blog / #5 no learning :(
on Monday, September 11th, 2023 12:21 | by Ellie
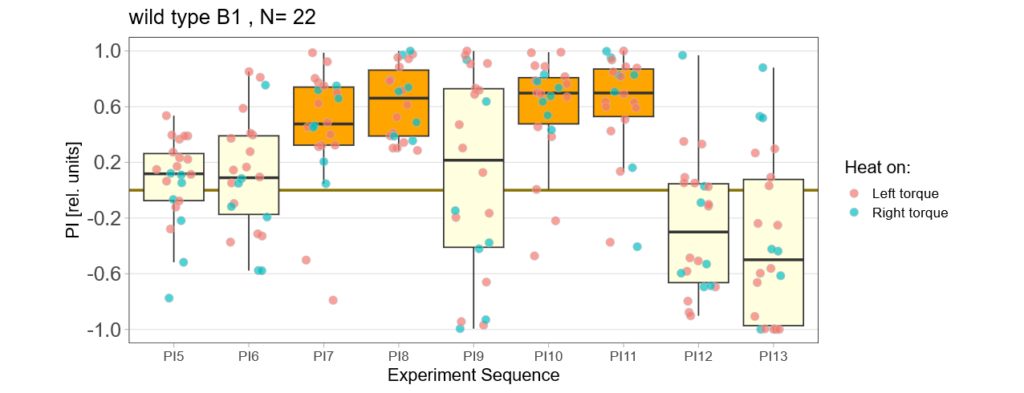
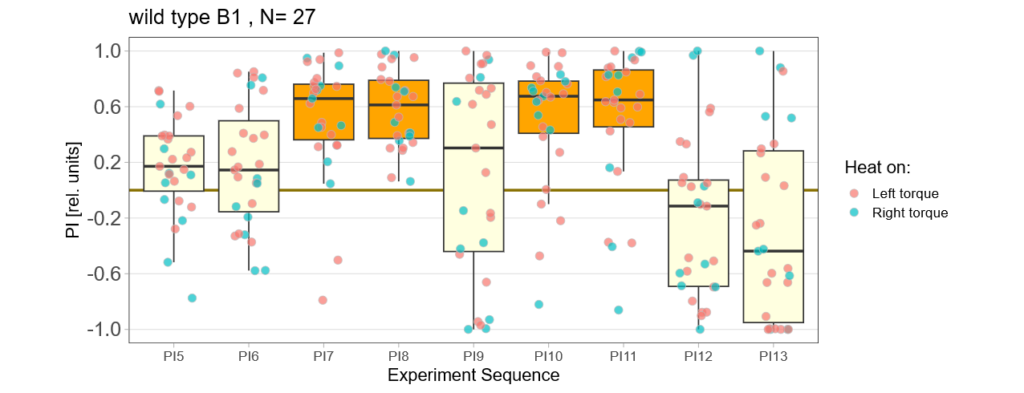
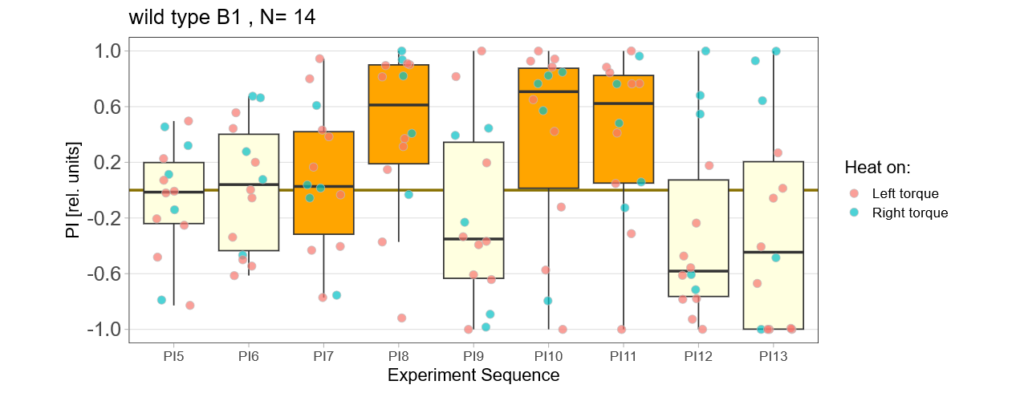
Below you find the data from my experimental rounds A and B:
-> learning scores of the parental flies from experimental round A and B
-> learning scores of the trained parent´s offspring only from experimental round A
-> learning scores of the untrained parent´s offspring only from experimental round A
The results confuse me a lot and I am happy to discuss reasons :) However the offspring of the round-B will be ready for testing by the end of this week so there is still some data to collect…
Cloning via DNA Assembly
on Friday, September 1st, 2023 7:26 | by Isabel Stark
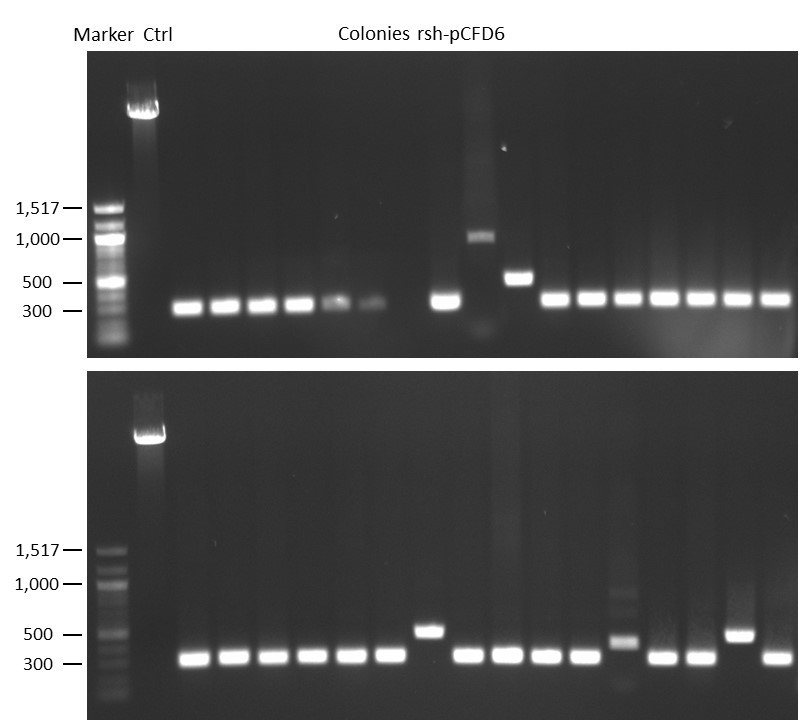
DNA Assembly in a 1:2 ratio of vector to insert with gRNAs of rsh and rut (Q5 and template concentration: 640 pg/µl) and 100ng of pCFD6 BbsI AP (using QuickCIP). Heat-shock (hs) transformation into E. coli (DH5α competent) with 10 µl Assembly Reaction and 100 µl cells.
For Crtl, pCFD6 BbsI AP was wrongly used.
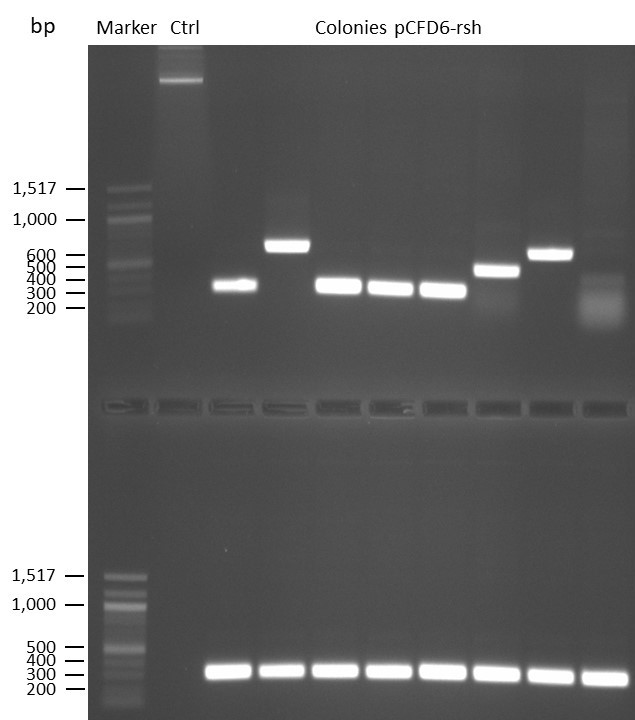
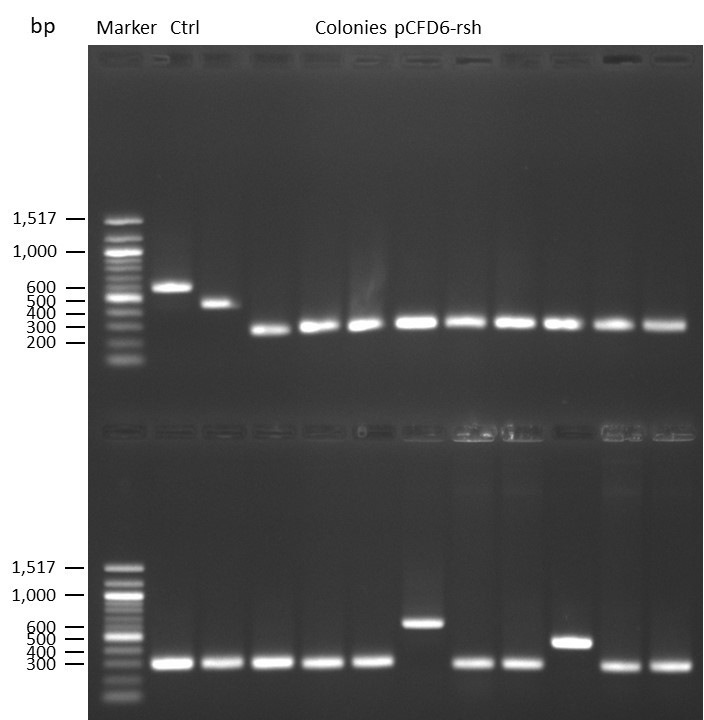
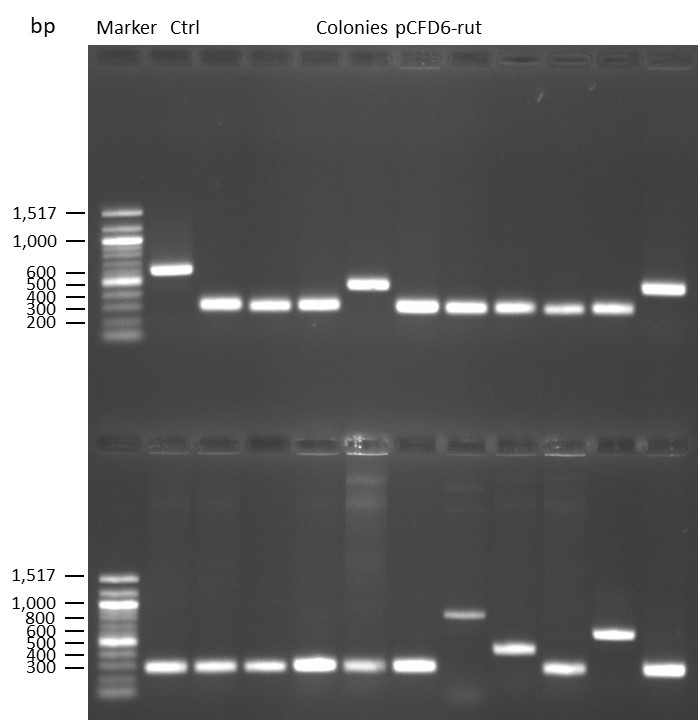
DNA Assembly in a 1:2 ratio of vector to insert with the gRNAs of rsh and rut (Q5 and template concentration: 640 pg/µl) and 100ng of pCFD6 BbsI AP (using FastAP and 2 extraction steps). Heat-shock (hs) transformation into E. coli (DH5α competent) with 10 µl Assembly Reaction and 100 µl cells.
For Crtl, pCFD6 BbsI AP was used in reaction.
Category: genetics, Memory, Operant learning, operant self-learning, Radish | No Comments